
Claude Code : comprendre et maîtriser ses tokens
Ajout des plugins rtk et codeburn
Quoi ?! déjà ?!
Je ne compte plus le nombre de fois où je l'ai dit (plus ou moins à haute voix) en voyant mon quota Claude Code de 5h atteint en 2-3 prompts.
Si parfois la taille de la codebase pouvait l'expliquer en partie, ainsi que le joli "conso x2" des peak hours, par moment j'explosais le quota tôt le matin sur des petites bases. Je suis sûr que c'est arrivé au moins une fois à tout le monde.
Et derrière ces quotas explosés, le même problème : les tokens. Input token / output token, pourquoi mon prompt passe subitement de 500 tokens à 20k d'un coup.
Mais du coup c'est quoi exactement un token ? Qu'est-ce qui en génère le plus ? Comment réduire leur consommation pour profiter mieux de mon quota ?
Sous le capot de Claude Code
Token ? Késako ?
Le token est une unité utilisée par les LLM pour lire et générer du texte. Le token n'est pas spécifique à Claude Code, GPT et les autres utilisent aussi cette unité.
Quand vous écrivez du texte, ou faites lire du texte/code à Claude, il va découper l'entrée en tokens. OpenAI vous donne la possibilité de voir comment ils découpent vos prompts en tokens depuis leur tokenizer.
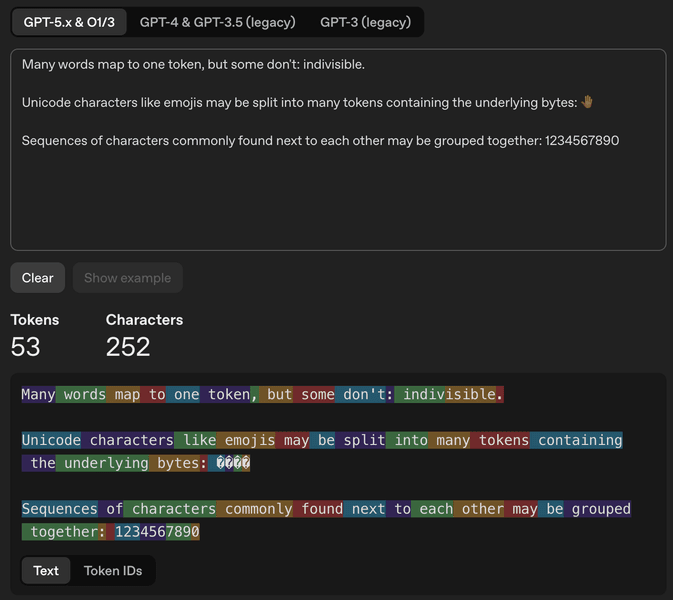
Attention en revanche, la façon de découper en tokens diffère d'un modèle à l'autre ; ainsi Claude ne découpe pas de la même manière qu'OpenAI par exemple. Mais en moyenne, on estime qu'un mot équivaut à 1,3 token en anglais, et environ 2 tokens pour un mot français.
Ça c'est pour du prompt classique quand vous discutez naturellement avec votre LLM préféré, mais dans le cas du code, la densité de tokens sera bien supérieure. Les tokenizers modernes regroupent les séquences fréquentes en un seul token — un mot courant en anglais devient souvent 1 token. Mais le code fragmente bien plus : les opérateurs, les noms de variables courts, les indentations et les séquences symboliques (=>, !=, ::) génèrent chacun leur propre token là où le texte naturel les compresserait. Résultat : à nombre de caractères égal, un fichier de code consomme systématiquement plus de tokens qu'une phrase en prose.
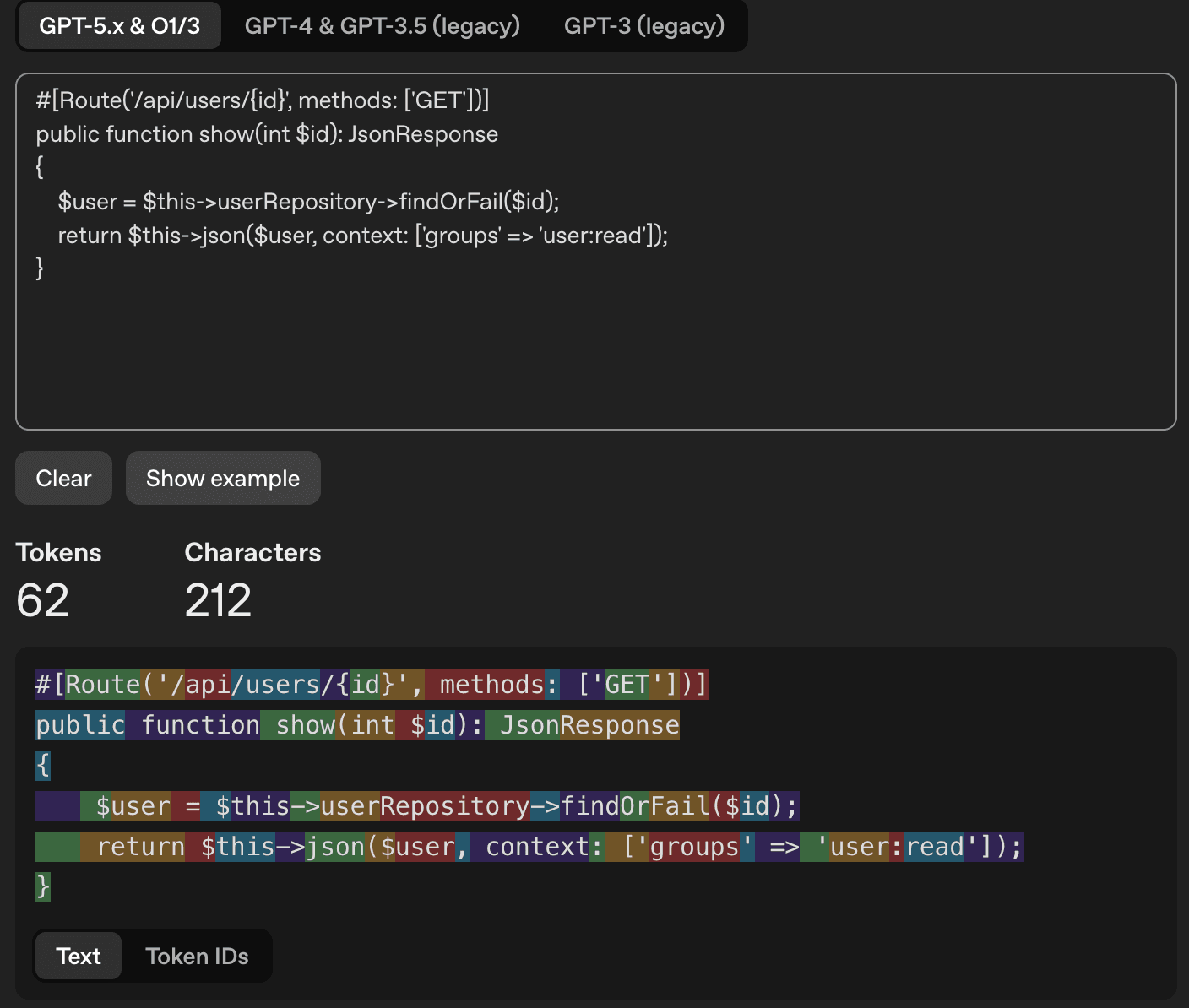
Pour un extrait de code avec moins de caractères que le texte précédent, on voit bien que plus de tokens ont été utilisés.
Input / Output Tokens
Claude et les autres LLM différencient les tokens en 2 catégories :
- Les input tokens : les tokens utilisés pour lire votre prompt ou le code analysé par exemple
- Les output tokens : les tokens utilisés pour générer la réponse (le code par exemple)
Généralement ces 2 catégories ont des prix différents : les input tokens coûtent moins cher que les output tokens au million de tokens. Sur les modèles Claude 4 actuels (Sonnet, Opus), le ratio est d'environ 1:5 — un output token coûte cinq fois plus cher qu'un input token. Ce ratio peut varier selon les modèles, mais l'ordre de grandeur reste stable. Cela vient du fait que produire du texte ou du code nécessite bien plus de ressources que d'en lire.
Pour réduire ce coût, Claude utilise un mécanisme de prompt caching : les portions de contexte qui ne changent pas entre deux requêtes (system prompt, CLAUDE.md, définitions des tools...) sont mises en cache. Les injections silencieuses au démarrage bénéficient largement de ce cache — elles ne sont pas recalculées à chaque prompt.
Context window
On a vu ce que sont les tokens et à quoi ils servent, maintenant on va voir comment Claude et les autres LLM gèrent leur "mémoire", et leur mémoire c'est la context window. La context window représente l'ensemble de tokens que Claude peut garder en mémoire. Pour la majorité des utilisateurs payants, cette limite est de 200K tokens. Certains plans donnent accès à des fenêtres plus larges (500K sur Enterprise, 1M sur des modèles spécifiques avec usage credits activés), mais 200K est la référence que vous rencontrerez dans la plupart des sessions Claude Code. Cette limite englobe à la fois les input tokens ET les output tokens.
Et cette limite peut très vite être atteinte : plus Claude doit lire votre codebase, utiliser des outils, et plus vous allez utiliser la même session, plus votre contexte va se remplir. D'autant plus qu'à chaque itération, Claude renvoie le contexte précédent.
Par exemple, vous écrivez un prompt de 200 tokens, Claude utilise 2000 tokens pour répondre (utilisation d'un outil + génération de la réponse), votre contexte contient 2200 tokens. Vous n'êtes pas satisfait, vous écrivez un nouveau prompt de 800 tokens → Claude renvoie les 2200 précédents + les tokens pour la nouvelle réponse, et ainsi de suite.
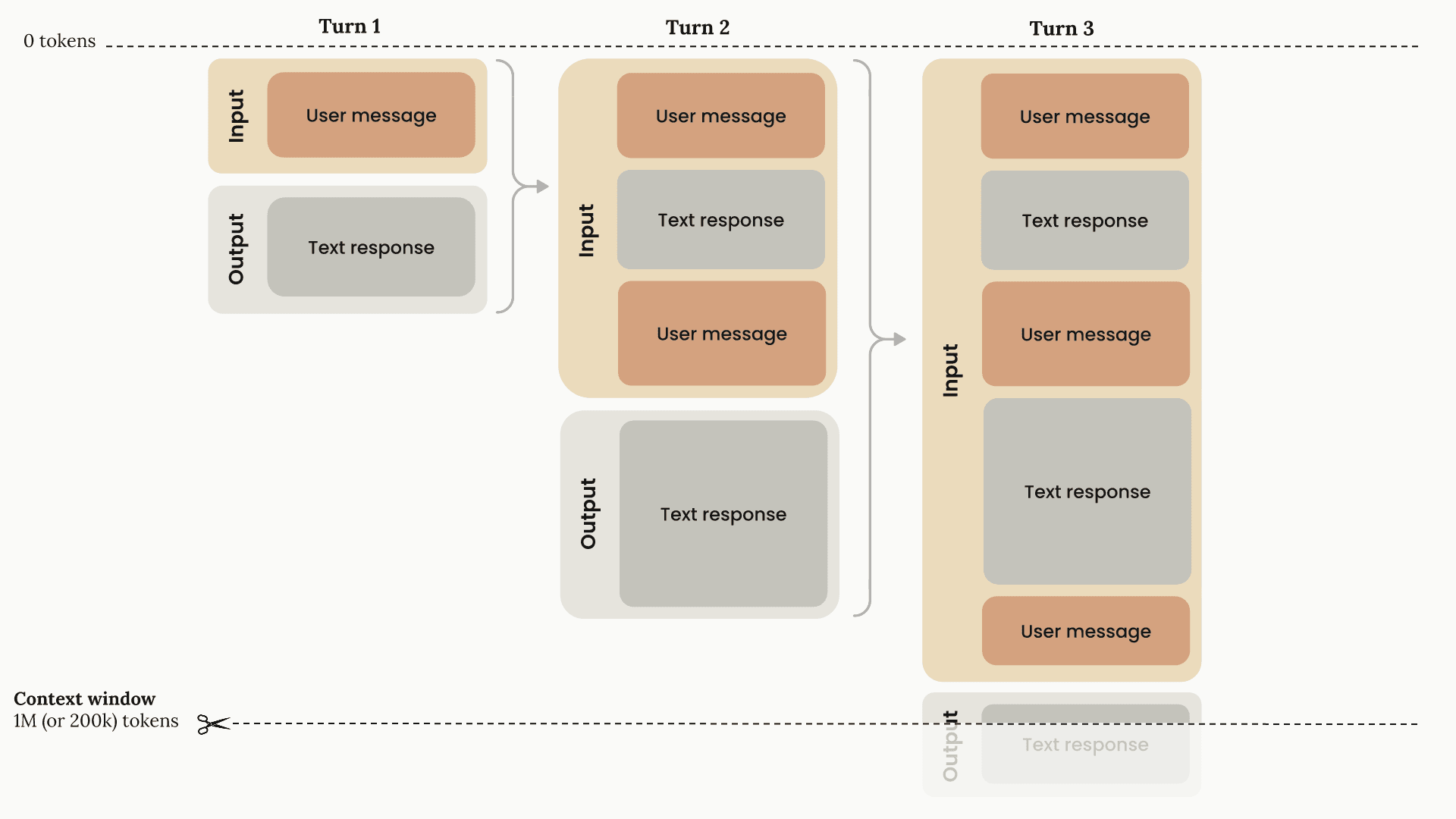
Et cette context window n'est pas extensible. Une fois la limite atteinte, Claude va supprimer les tokens les plus anciens et donc perdre du contexte et c'est là que l'IA peut commencer à perdre en précision, voire halluciner.
Une context window est limitée à la session en cours. Dès que vous quittez Claude et le relancez, cette context window revient à zéro et Claude ne se souvient plus de rien. Seule exception partielle : si vous utilisez les memory files (comme CLAUDE.md), leur contenu est réinjecté automatiquement au démarrage de chaque session. Ce n'est pas de la mémoire à proprement parler parce que Claude ne se "souvient" de rien, c'est simplement du contexte persistant qui sera chargé dès le premier prompt.
Ce que Claude injecte silencieusement
On a les tokens, la context window. On a vu que la context window pouvait très vite grossir en fonction de la taille du prompt, de la codebase, etc. Mais derrière votre prompt, Claude va utiliser tout un tas de tokens sans vous le montrer. Et ces tokens, vous pouvez les voir via la commande /context. Faites un essai pour voir, tapez la commande dans une session Claude vierge. Ex chez moi :
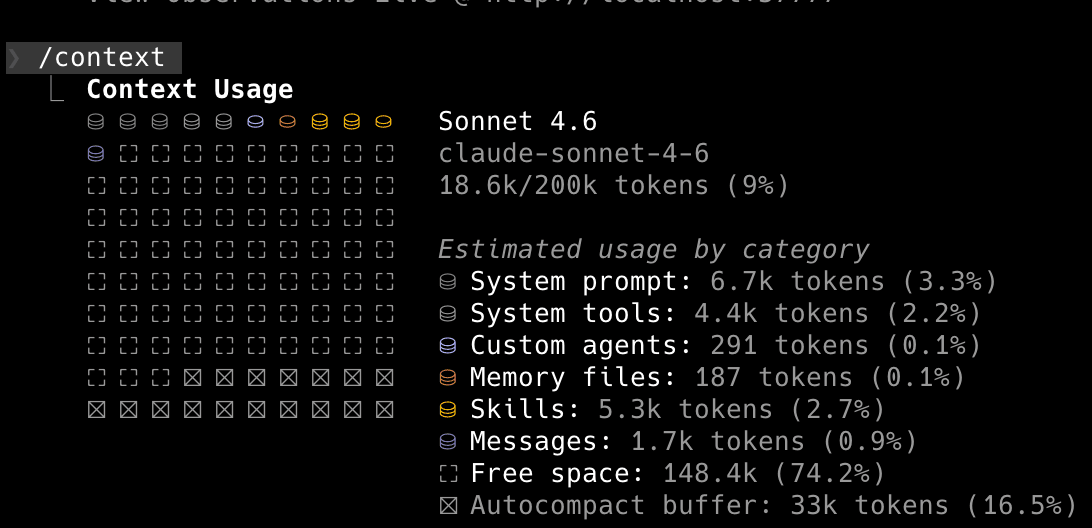
On voit que par exemple chez moi, avant même d'avoir écrit un prompt, j'ai 9% du contexte qui est déjà rempli.
Mais pourquoi Claude a consommé 9% du contexte alors que je n'ai rien demandé ? Parce que dès le début, Claude injecte pas mal de choses :
- Votre
CLAUDE.mdet autres memory files - Les définitions des MCP tools configurés (chaque serveur MCP ajoute ses définitions à chaque session)
- Les plugins
- Les custom agents définis dans votre projet
- Le system prompt de Claude Code lui-même
Et tout ça peut vite remplir votre context window avant d'avoir commencé à travailler. Et comme on a dit que chaque prompt renvoie le contexte précédent, votre premier prompt consommera déjà minimum 18k tokens (dans mon exemple).
Ensuite, à chaque demande, Claude injectera en plus les fichiers dont il a besoin, consommera des tokens supplémentaires s'il doit charger d'autres tools, utiliser des MCP, exécuter des commandes, etc.
Ce que vous verrez aussi dans /context, c'est une ligne Autocompact buffer — un espace réservé (~16% de la context window) que Claude Code met de côté exclusivement pour le processus de compaction. Il n'est pas utilisable pour votre travail. Autrement dit, sur une context window de 200K tokens, votre espace de travail réel démarre déjà réduit d'environ 33K tokens, avant même d'avoir écrit un premier prompt.
Pour limiter la casse, Claude dispose d'un outil.
L'autocompact
Claude Code n'attend pas d'atteindre la limite pour agir. L'autocompact se déclenche par défaut aux alentours de 83% de la context window, en conservant une réserve d'environ 13 000 tokens pour pouvoir terminer la réponse en cours avant de compacter. C'est pour ça qu'on peut être surpris de voir la compaction se déclencher "tôt" parce que Claude anticipe.
En pratique, Claude va compresser le contexte et générer un résumé de la session, plus compact, qui utilise moins de tokens. Et c'est ce résumé qui sera envoyé à chaque prompt plutôt que l'intégralité du contexte précédent.
Ça va en effet réduire les tokens envoyés à chaque fois, mais ça reste un résumé généré par Claude, avec les problèmes que ça implique : tout n'y est pas, et c'est là que Claude va commencer à partir un peu dans tous les sens. Il peut oublier qu'il a déjà traité certains éléments, reposer une question à laquelle vous avez déjà répondu, se contredire lui-même, etc.
Il existe aussi une commande /compact que vous pouvez déclencher manuellement pour faire cet compaction.
Et pour palier à ce problème de grossissement, Claude dispose d'un autre outil.
Les sub-agents
Plutôt que de se gaver de contexte, Claude peut utiliser des sub-agents. Ce sont des sous-sessions spécialisées dans une tâche avec leur propre contexte. Quand vous ferez une demande de feature, Claude va typiquement pouvoir créer différents sub-agents spécialisés, qui utiliseront chacun les outils nécessaires, plutôt que tout faire dans la session principale :
⏺ 6 Agents finished (ctrl+o to expand)
├─ Explore backend codebase · 23 tool uses · 104.5k tokens
│ ⎿ Done
├─ Explore frontend codebase · 28 tool uses · 108.0k tokens
│ ⎿ Done
├─ Write backend part · 4 tool uses · 20.0k tokens
│ ⎿ Done
├─ Write frontend part · 1 tool uses · 18.6k tokens
│ ⎿ Done
├─ Write unit tests · 7 tool uses · 64.0k tokens
│ ⎿ Done
└─ Write documentation · 24 tool uses · 52.7k tokens
⎿ Done
L'avantage c'est que peu importe combien de tokens chaque sub-agent va consommer, votre session principale ne recevra qu'un résumé. Si vos agents consomment tous 150K tokens, ils n'iront pas remplir le contexte de votre session principale et n'enverront qu'un résumé de quelques tokens.
L'inconvénient... c'est que ça peut vite faire exploser votre quota.
Économiser vos tokens
On a vu qu'il était très facile d'exploser sa consommation de tokens, et donc par la même occasion, son quota. Même si vous aurez moins ce souci sur des plans MAX, on n'a pas tous les moyens de se payer ces plans, donc on doit être attentif à ses tokens.
CLAUDE.md : la mémoire de votre projet
CLAUDE.md, c'est LE fichier le plus important de votre projet. C'est lui qui va donner les informations nécessaires à Claude pour générer le code tel que vous le voulez, qui va lui donner l'architecture de votre projet, votre stratégie de naming/branching git, comment rédiger et exécuter les tests, etc. Tout ça vous fera économiser beaucoup d'input tokens (Claude aura moins besoin de "deviner" ce qu'il doit faire en analysant votre codebase) et d'output tokens (comme il sera guidé par le CLAUDE.md, il y aura moins d'allers-retours à faire).
Attention cependant : chaque token présent dans votre CLAUDE.md sera injecté et relu au démarrage de chaque session. Un CLAUDE.md de 5 000 tokens, c'est 5 000 input tokens consommés avant même d'avoir écrit un prompt. ET c'est à multiplier par le nombre de sessions sur votre journée. Il doit rester court et précis : évitez d'en faire une documentation complète de votre projet.
Gérer la taille de vos sessions
Claude renvoie systématiquement le contexte précédent à chaque tour. Deux commandes permettent de gérer ça, avec des comportements très différents :
/compact: compresse l'historique en un résumé. Le fil de la session est conservé, Claude sait ce qui a été fait. À utiliser quand vous voulez continuer sur le même sujet mais libérer un peu d'espace. Vous pouvez lui passer une instruction pour guider le résumé :/compact retain the architecture decisions./clear: remet le contexte à zéro. Claude ne se souvient plus de rien. À utiliser quand vous changez de feature.
Règle simple : /compact pour continuer, /clear pour repartir.
Une dernière commande : /cost. Elle affiche la consommation en tokens et le coût estimé de la session en cours. Pratique pour visualiser en temps réel combien une session un peu trop bavarde vous a coûté.
Guider Claude
Claude Code ne lit pas votre codebase en entier à chaque demande. Il utilise des outils de recherche pour trouver les fichiers dont il a besoin. Ce sont ces appels d'outils qui consomment des tokens : localiser un fichier, lire son contenu, en chercher un autre... Sur une grosse codebase, cette exploration peut représenter plusieurs milliers de tokens, parfois juste pour trouver un fichier.
Avec @path/to/file, vous sautez cette exploration : Claude reçoit directement les fichiers sans avoir à les chercher. Lors d'une feature ou d'un bugfix, identifiez en amont les fichiers à modifier et ceux qui serviront de référence.
.claudeignore : exclure ce qui est inutile
À l'instar d'un .gitignore, vous pouvez créer un fichier .claudeignore à la racine de votre projet pour exclure des fichiers et dossiers. La syntaxe est identique. Il est par exemple plutôt recommandé d'exclure node_modules de vos projets front, .nuxt ou encore vendor et var de vos projets Symfony.
node_modules/
/var
.nuxt
Planifiez vos développements
Très utile pour vos grosses features, la planification. Faites analyser le code par Claude avant de développer, planifiez les étapes de développement, ne laissez aucune place au doute. Le but est de détailler clairement le cheminement pour développer la feature, ce qui doit impérativement être fait, ce qui ne doit pas être fait, les fichiers importants à lire, etc. Un plan va souvent se découper comme suit :
- Phase de découverte
- Les fichiers importants dont Claude doit prendre connaissance
- Les anti-patterns
- Les APIs externes à utiliser
- Phases 1 à X
- Découpage en phases du développement (phase 1 back, 2 front, 3 tests) avec pour chacune les détails pour implémenter
Et ça tombe bien, Claude Code dispose d'un outil natif pour ça : le plan mode, activé avec la commande /plan (ou Shift+Tab deux fois). C'est un mode lecture seule où Claude peut lire vos fichiers, analyser votre codebase, poser des questions, mais il ne peut ni modifier de fichier, ni exécuter de commande. Il produit un plan que vous relisez, affinez, puis validez. Ce n'est qu'après votre validation qu'il sort du plan mode et exécute.
Même si ça peut paraitre contre intuitif de génèrer un gros plan, l'économie de tokens est réelle : une implémentation ratée coûte les tokens de l'exploration initiale, ceux de l'implémentation incorrecte, ceux pour détecter l'erreur, et ceux pour la corriger. Le plan mode permet d'anticiper tout ça.
Mixer les modèles
Il est tentant de laisser le meilleurs modéle tout faire. On se met opus, et on fait tout avec. Mais c'est inutile dans 90% des cas et surtout ça consomme énormément.
Une logique qu'on peut adopter : Opus pour planifier, Sonnet pour exécuter. On va laisser le modèle le plus avancé planifier notre tâche, et Sonnet sera largement suffisant pour éxécuter le plan.
La différence de tarif est significative : Sonnet 4.6 est 40% moins cher par token en entrée et 40% moins cher par token en sortie qu'Opus. Et comme la majorité des tokens d'une session de développement sont consommés pendant l'exécution le gain est important par rapport à une session complète sur Opus.
Claude Code intègre ce pattern nativement avec la commande /model et l'option opus-plan :
/model opus-plan
En activant cette option, Claude Code route automatiquement les tâches de planification vers Opus et les tâches d'exécution vers Sonnet dans la même session. Vous n'avez pas à changer manuellement de modèle ni à gérer deux contextes séparés.
En pratique, ça donne :
- Vous décrivez votre feature → Opus analyse, raisonne, produit le plan
- Vous validez le plan → Sonnet prend la main pour l'implémentation
Un plan coûte quelques centaines de tokens. Un diff incorrect de 400 lignes que vous annulez et régénérez en coûte des milliers, deux fois, plus les tours pour expliquer ce qui n'allait pas.
Arrêtez de papoter
C'est pas l'astuce la plus folle pour économiser des tokens, mais arrêtez de parler à Claude Code comme si c'était votre collègue ! Soyez moins verbeux dans vos prompts, je vois encore beaucoup de collègues écrire leur prompt comme on rédige un ticket de bug.
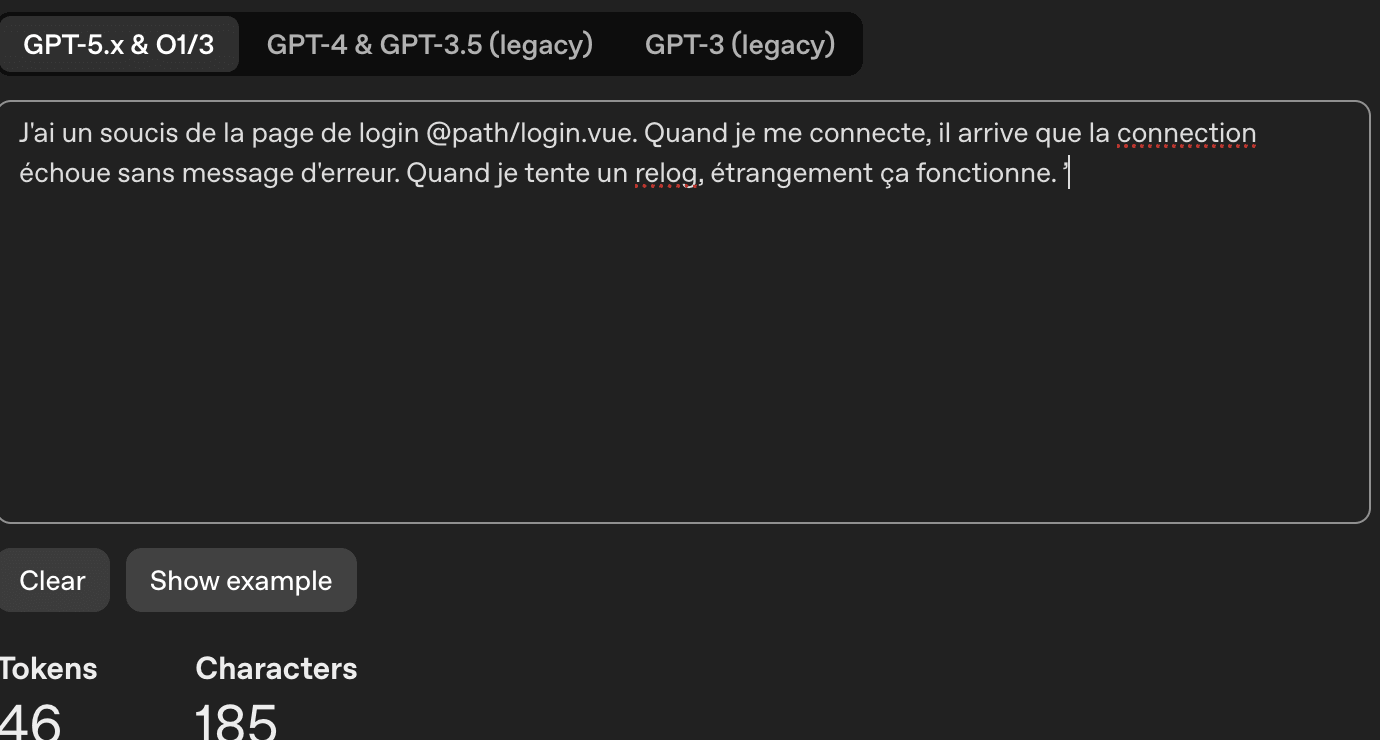
C'est une IA en face, pas besoin d'être aussi verbeux. On peut être plus direct.
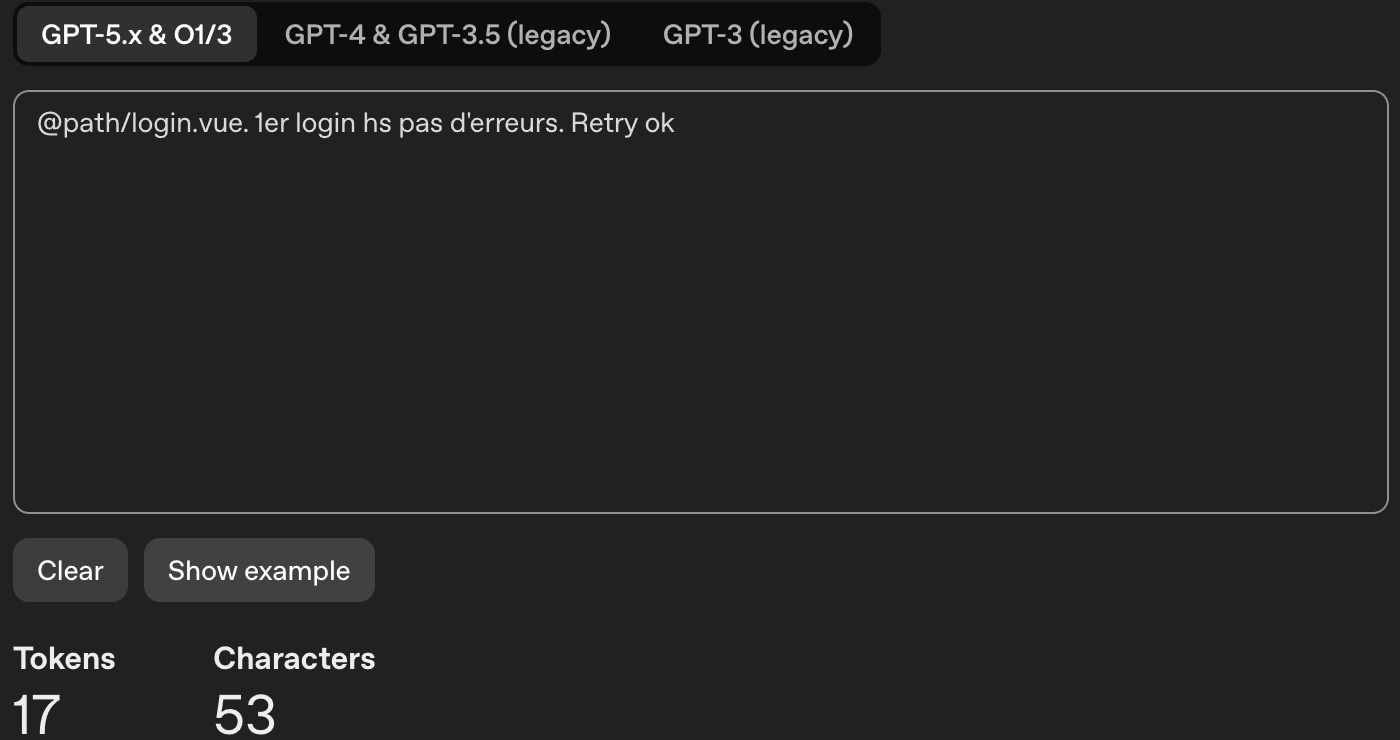
La différence est assez importante. Là, c'est un peu forcé pour l'exemple et c'est un petit prompt, mais imaginez sur un gros plan le nombre de tokens perdus...
Quelques outils pratiques
Claude-mem, une mémoire pour claude
On a dit plus haut qu'une context window repart à zéro entre deux sessions, et que seul le CLAUDE.md persistait. C'est vrai par défaut. Mais il existe un plugin qui change ça : claude-mem.
claude-mem est un plugin Claude Code qui capture automatiquement ce que Claude fait pendant vos sessions de code, compresse ces observations, et les réinjecte comme contexte dans les sessions suivantes. Le tout stocké localement dans une base SQLite.
EN gros : vous bossez deux heures sur un bug d'authentification, vous fermez Claude Code, vous revenez le lendemain. La prochaine session démarre déjà en sachant ce sur quoi vous avez travaillé. Le bug que vous aviez corrigé la veille ? Claude s'en souvient. Il ne va pas relire les fichiers déjà analysés, ni retomber sur les mêmes mauvaises hypothèses que vous auriez déjà éliminées.
Ce qui rend claude-mem intéressant par rapport à une simple injection dans le CLAUDE.md, c'est la compression : la transcription brute d'une longue session peut représenter des dizaines de milliers de tokens. claude-mem la distille en observations courtes et typées (bugfix, décision, découverte), pour que le rappel coûte très peu.
Installation :
# Depuis une session Claude Code
/plugin marketplace add thedotmack/claude-mem
/plugin install claude-mem
Caveman, retour à l'âge de pierre
Si vous avez déjà demandé à Claude Code d'écrire une petite fonction et qu'il vous a répondu avec trois paragraphes d'introduction avant d'écrire une ligne de code — vous voyez le problème. Ces tokens de politesse, de contextualisation et de reformulation, c'est du gaspillage pur.
C'est l'idée derrière caveman : un skill Claude Code qui fait parler l'agent comme un homme des cavernes — supprime le remplissage, garde la substance, utilise des fragments. Ça coupe environ 75% des output tokens en gardant une précision technique intacte.
La logique est simple : caveman n'affecte que les output tokens — les tokens de raisonnement ne sont pas touchés. Caveman ne rend pas le cerveau plus petit. Il rend la bouche plus petite.
Il existe plusieurs niveaux d'intensité :
- lite : supprime juste les formules de politesse et le remplissage
- full : passe en style fragmenté
- ultra : compression au maximum, utile quand chaque token compte, moins lisible pour déboguer une erreur complexe. Un vrai homme des caverne, grrrr
Et en bonus : Caveman Compress est une feature séparée qui réécrit votre CLAUDE.md en caveman-speak, ce qui réduit les input tokens plutôt que les output tokens. Fonctionne aussi sur n'importe quel autre fichier que vous lui passez, comme un plan sauvegardé par exemple.
Installation :
/plugin marketplace add JuliusBrussee/caveman
/plugin install caveman@caveman
Puis dans une session :
/caveman # mode par défaut
/caveman lite # supprime juste le remplissage
/caveman full # réponses en fragments
/caveman ultra # compression maximale
Pour être honnête, ça vous fera économiser ques centaines de token, donc c'est pas game changer. Non. Le vrai avantage de caveman c'est plutôt la vitesse de lecture et la limitation du bruit.
Tokscale, visualiser votre rentabilité
On ne peut pas optimiser ce qu'on ne mesure pas. /cost vous donne le coût de la session en cours, mais rien sur vos tendances sur la semaine ou du mois.
tokscale comble ce manque. C'est un outil CLI avec une interface interactive qui agrège votre consommation de tokens à travers toutes vos sessions Claude Code, et vous la présente sous plusieurs angles :
- Overview : consommation totale, coût estimé, tendance
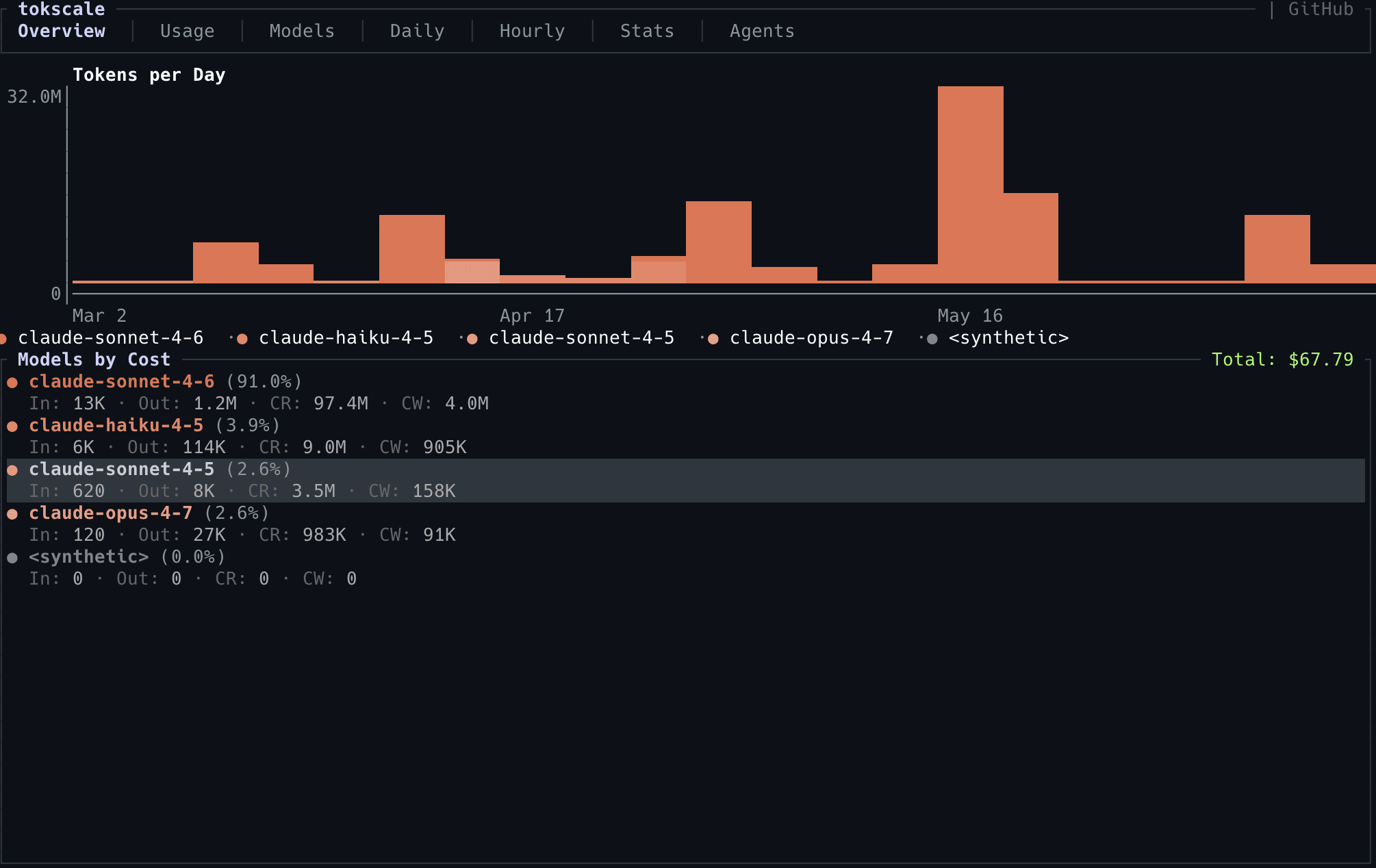
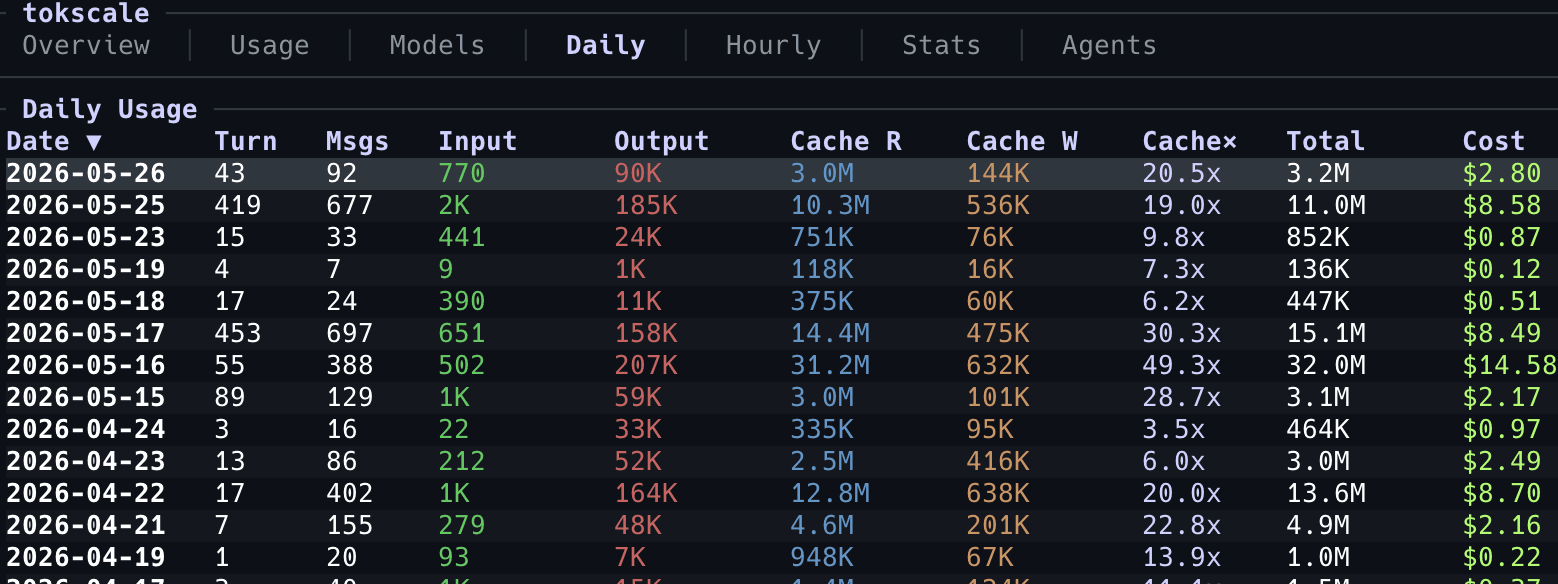
- Daily / Hourly : identifier les journées ou plages horaires où vous sur-consommez
- Models : répartition par modèle (utile si vous mixez Sonnet et Opus)

- Agents : détail par session et par agent

Ce qui est pratique : tokscale ne se connecte à aucun service externe, il lit directement les logs locaux de Claude Code. Et si vous utilisez d'autres outils (Cursor, Gemini CLI, Codex...), il agrège tout au même endroit.
Installation :
npm install -g tokscale
Puis :
tokscale # vue interactive complète
tokscale --week # consommation sur 7 jours
tokscale --client claude # filtrer sur Claude Code uniquement
tokscale models # détail par modèle
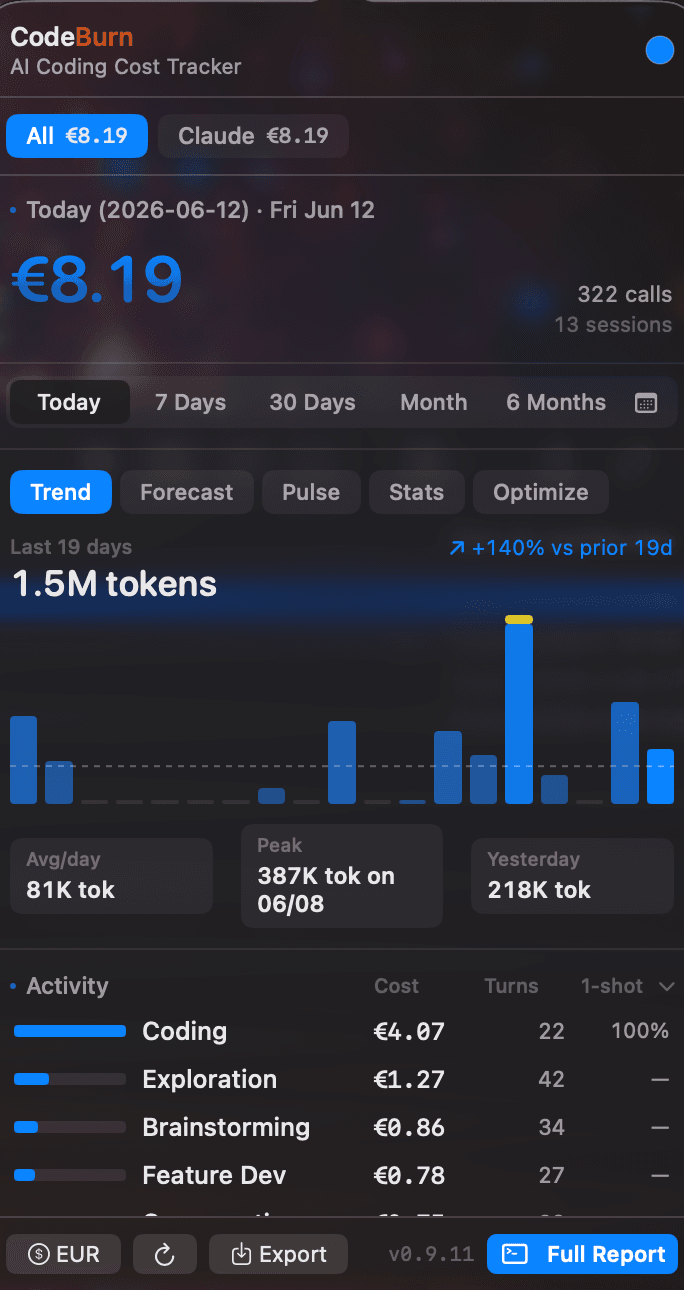
CodeBurn, le détail précis de vos conso
Un peu plus complet que tokscale. Codeburn de visualiser plus précisément où partent vos token, juste qu'au niveau de la tâche.
Il lit les transcripts de session stockés localement dans ~/.claude/projects/ et classe chaque échange en 13 catégories basées sur les patterns d'usage des tools.
Les catégories : coding, debugging, exploration, brainstorming — et surtout conversation, les échanges où Claude répond sans utiliser aucun tool. C'est là que la surprise arrive : pour le créateur de l'outil, qui dépensait 200$/jour sur Claude Code sans visibilité, plus de la moitié du budget partait en pure conversation, pas en génération de code.
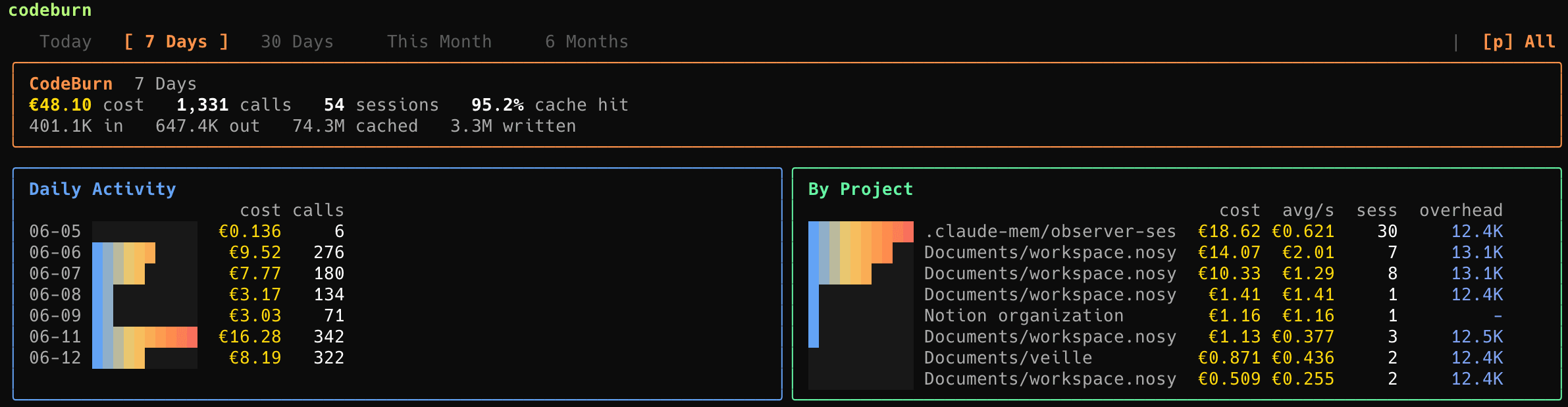
CodeBurn est open source et tourne entièrement en local. Il propose un dashboard TUI interactif avec support macOS menu bar via SwiftBar, export CSV/JSON, et breakdown par projet, modèle, tool, et serveur MCP.
npx codeburn
RTK (Rust Token Killer)
RTK prend le problème à un endroit que personne n'avait adressé : les outputs CLI que Claude injecte dans le contexte.
L'idée est simple : la plupart des outputs CLI envoyés au LLM sont du bruit : tests qui passent, logs verbeux, progressbar, etc. RTK est un proxy CLI qui filtre et compresse ces outputs avant qu'ils atteignent la context window.
Les chiffres publiés par l'auteur sont assez impressionnants : cargo test passe de 155 lignes à 3 lignes (98% de réduction), git status de 119 à 28 caractères (76%). Sur un usage intensif c'est très vite rentable.
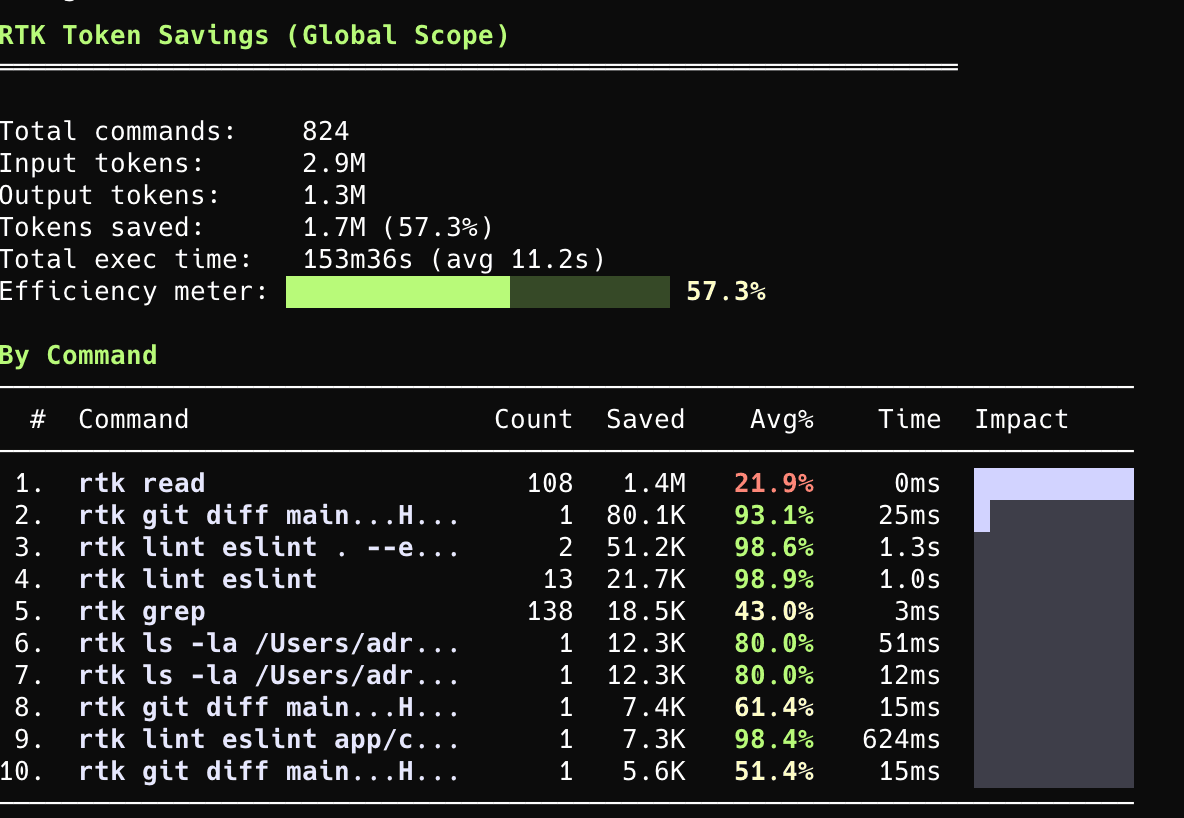
RTK s'installe en dehors de claude et va se brancher sur claude pour intercepter les requêtes. Il supporte plus de 100 commandes : git, pytest, cargo, docker, kubectl, eslint, tsc…
curl -fsSL https://raw.githubusercontent.com/rtk-ai/rtk/master/install.sh | sh
rtk init -g # installe le hook Claude Code
rtk gain # affiche les tokens économisés
La même commande d'init fonctionne pour Cursor, Codex, Windsurf, Gemini CLI — cohérent avec la philosophie de l'article : les principes s'appliquent à tous les outils LLM-based.
Pour finir
Voilà, vous en savez maintenant plus sur le fonctionnement de Claude, sur ce que sont les tokens, où ils partent, et comment bien les économiser.
Bien sûr, si vous êtes sur des plans MAX, la consommation de tokens n'est probablement pas votre priorité; et encore, avec les nouveaux modèles, même les plans MAX commencent à montrer leurs limites. Mais sur des plans inférieurs, vous avez désormais quelques outils pour profiter davantage de votre quota.
N'hésitez pas à consulter les sources en annexe pour aller plus loin, Claude Code est bien plus complexe quand on veut vraiment creuser les détails !
Mis à jour le